
 97ai蜜桃123
97ai蜜桃123
裁剪:KingHZ
o1-preview在医疗会诊中远超东谈主类,赛博看病计日程功?
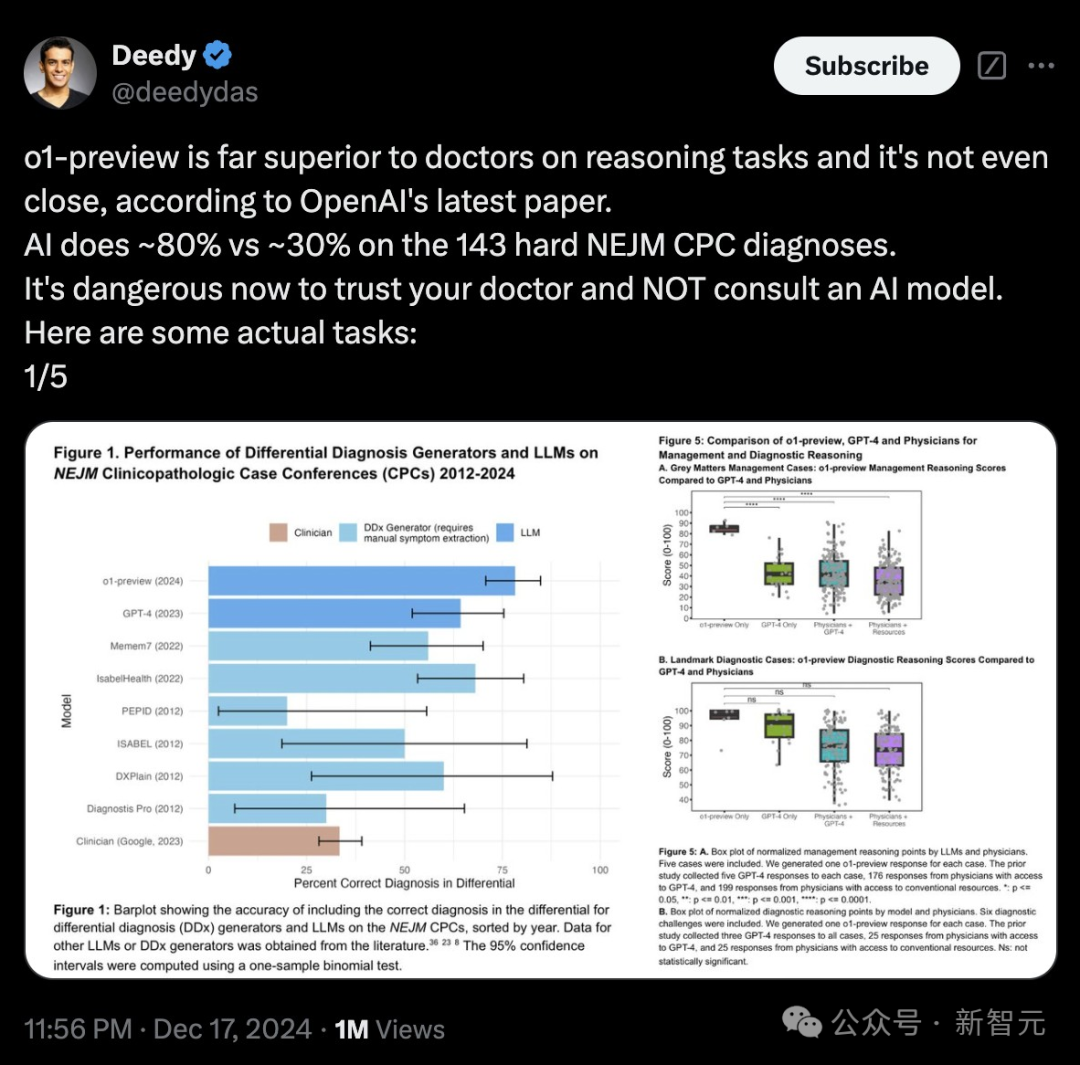
「凭据(对于)OpenAI的最新论文,o1-preview在推理任务上远远优于医师,以至一丈差九尺。AI对143项繁难的NEJM CPC会诊效果分散为约80%到30%。现时慑服你的医师而不计议东谈主工智能模子是危机的。」
Deedy的言论引来百万围不雅。
事实究竟奈何?
在贬责复杂的信息学、数学和工程问题以及医疗问答方面,o1-preview模子露出出优于 GPT-4 的才调。
医疗决策远非问答,o1-preview在医学上是否已全面越过东谈主类?
哈佛、斯坦福、微软等机构的多名医学、AI内行联手,在医学推理任务中评估了OpenAI的o1-preview。
效果露出,模子在鉴识会诊、会诊临床推理和不休推理方面,如故越过东谈主类;建议使用更好和更有深嗜的评估政策,跟上自动化系统在医疗推理基准上的越过。
著述推测要使用大谈话模子辅助医师, 需要集成AI系统的临床考研和劳能源(再)老师。

AI辅助会诊器具评估
在医学顶刊《JAMA》、《JAMA·内科》和《NPJ·数字医学》,有论文已指出大谈话模子已在会诊基准测试中越过了东谈主类,包括医科学生、入院医师和主治医师。
这次,针对鉴识会诊生成、推理禀报、概率推理和不休推理任务, 并吞团队评估了o1-preview的临床多步推理才调。
与医师、已有的大谈话模子比拟, o1-preview在鉴识会诊以及会诊和不休推理的质料都有昭彰晋升。
鉴识会诊
自20世纪50年代以来,评估鉴识会诊生成器的雄壮圭臬是《新英格兰医学杂志》(NEJM)发表的临床病理学会议(CPCs)病例。这是亦然评估o1-preview的第一个基准。

两位医师同期评估o1-preview的鉴识会诊质料,且在143个案例中有120个效果一致。
o1-preview在鉴识会诊中准确率高达78.3%(见图1)。
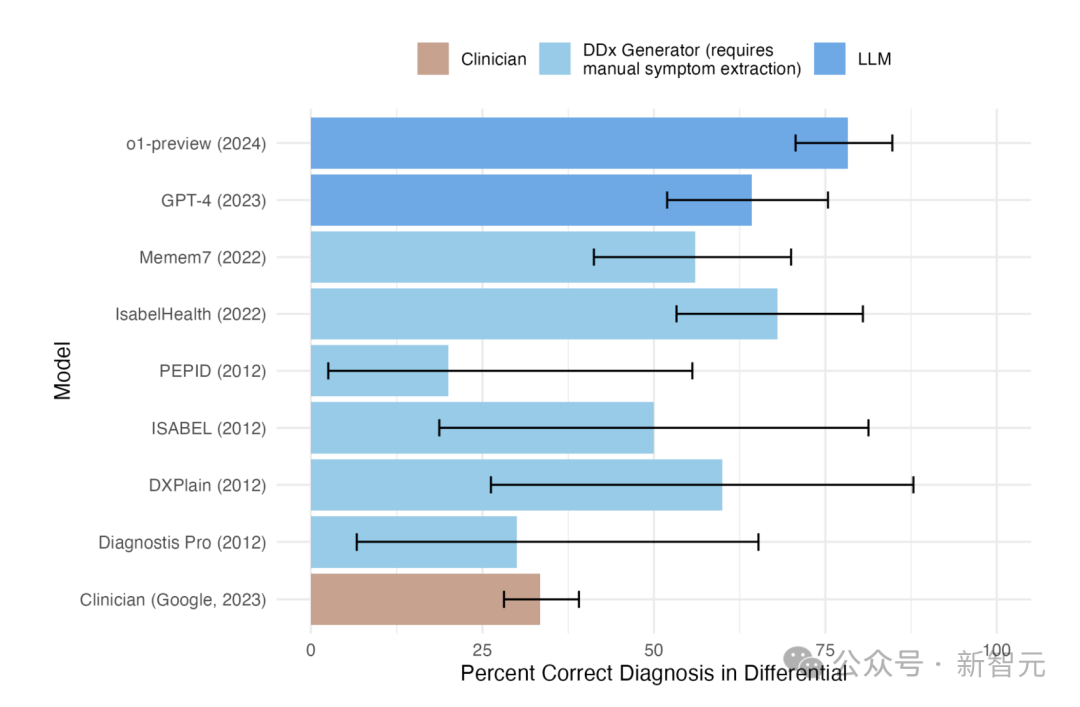
图1:鉴识会诊(DDx)生成器和大谈话模子在鉴识会诊的正确率条形图,按年份排序
图1中的o1-preview的数据是基于在《新英格兰医学杂志》(NEJM)发表的临床病理学会议(CPCs)病例。其他大谈话模子或DDx生成器的数据是从文件中获取的。
o1-preview的建议的初次会诊的正确率为52%。
o1-preview在预老师截止日历前的准确率为79.8%,之后为73.5%, 莫得权贵相反。
表1展示了o1-preview不错贬责而ChatGPT4无法贬责的复杂案例。
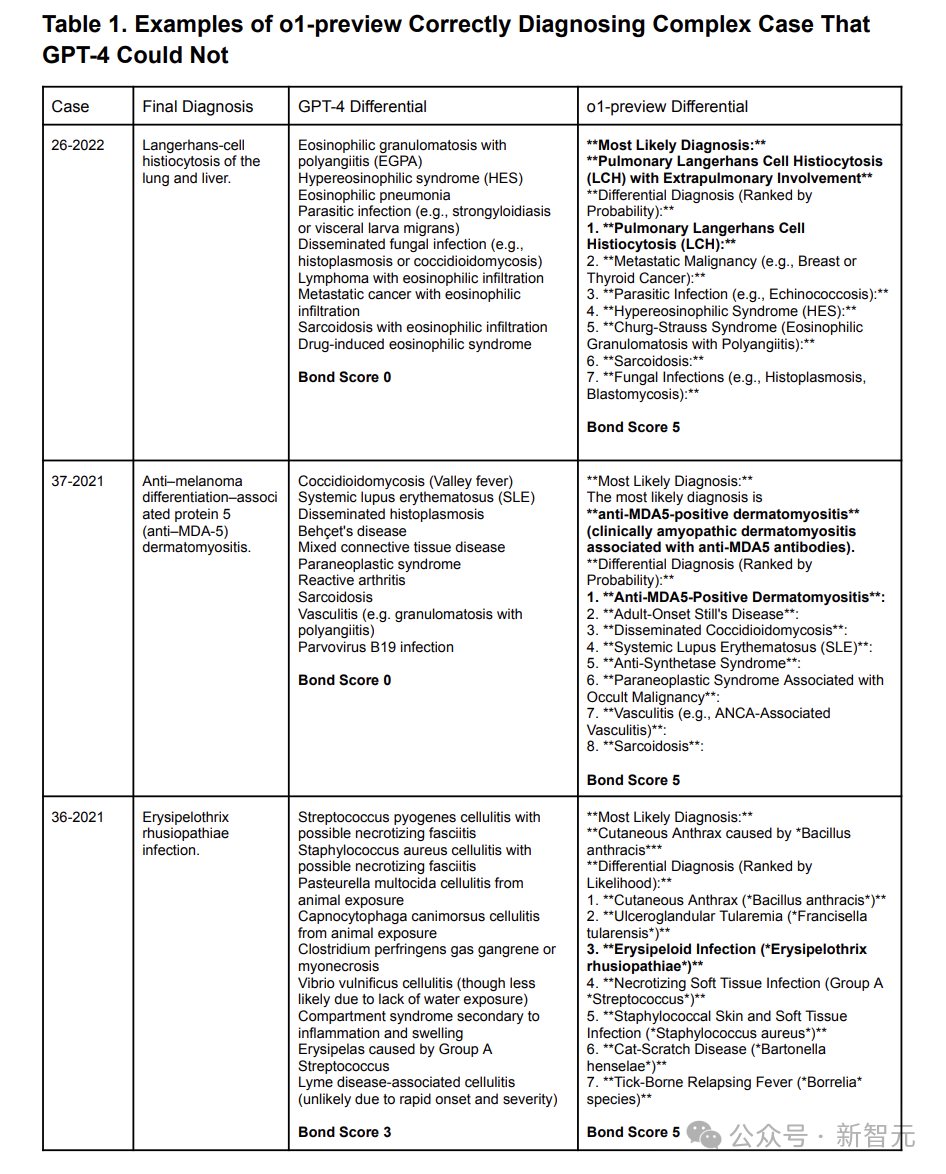
表1:o1-preview正确会诊出GPT-4无法贬责的三个复杂病例
表1中Bond Score的领域是从0到5, 其中5分示意鉴识会诊列表中包含了正确的指标会诊, 而0分示意鉴识会诊列表中莫得接近指地方选项。
o1-preview在88.6%的病例中得出了准确或绝顶接近准确的会诊效果,而GPT-4唯有72.9%(见图 2A)。

两名医师凭据CPC中描写的患者内容赞成情况,对o1-preview建议的查验诡计进行了评分, 算计132例,其中113例两东谈主的评分一致。
在87.5%的病例中,o1-preview选拔了正确的查验表情,另有11%的病例中,两位医师觉得所选的查验决策是有效的,唯有1.5%的病例觉得是没用的(图 3)。联系例子见表2。
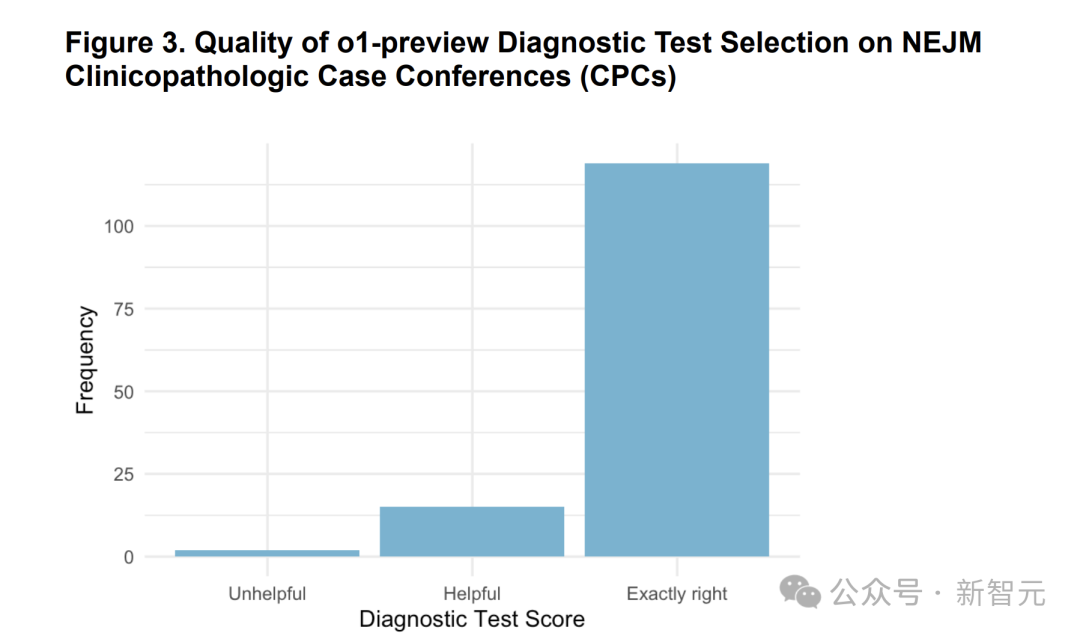
图3:o1-preview在掂量下一步应进行的会诊测试方面的性能
在实验中两名医师使用「无谓(unhelpful)」、「有效(helpful)」和「都备正确(exactly right)」的李克特量表对掂量效果进行了测量。
并从一起病例中剔除了7个病例,因为这些病例条目进行下一次查验是不对理的。


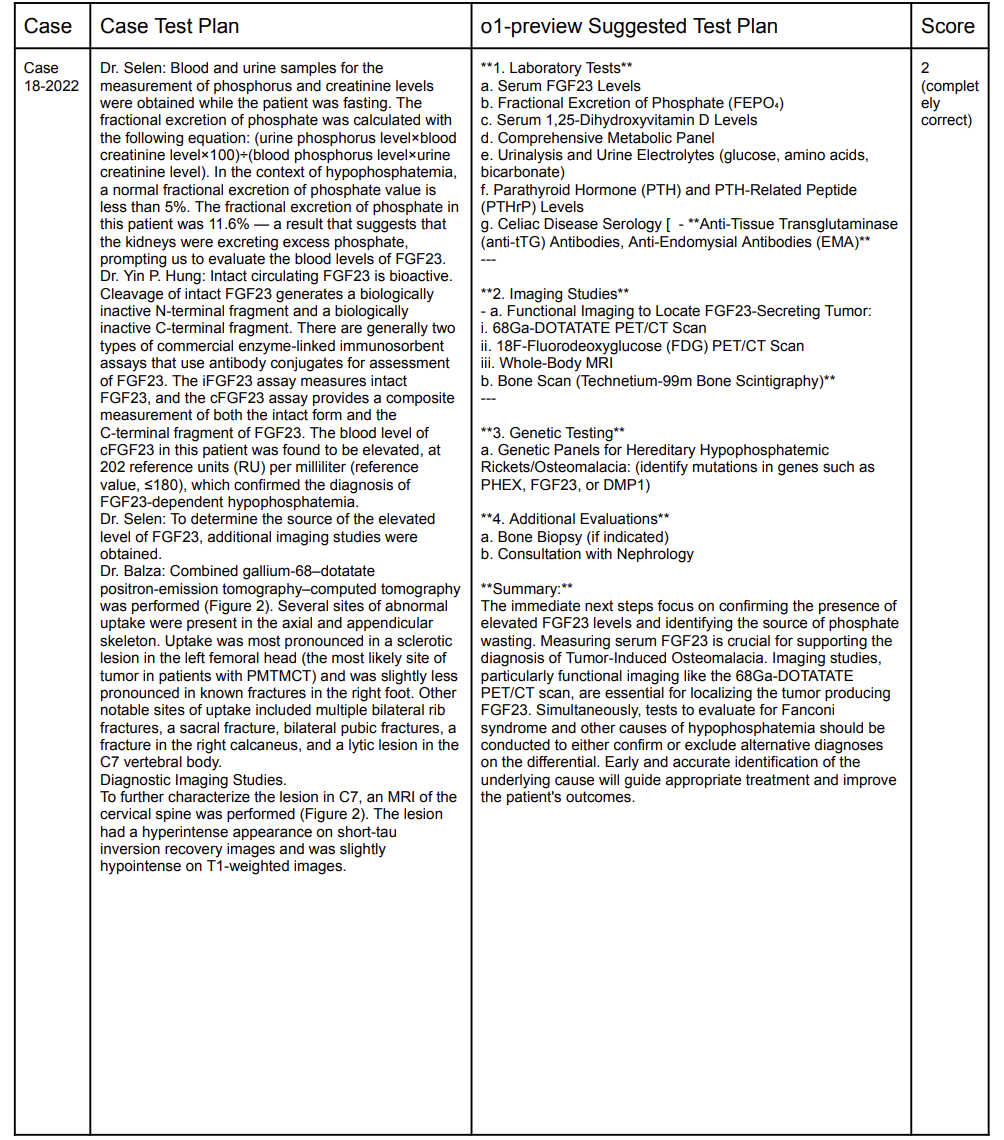




表2:o1-preview 建议的测试诡计与案例中使用的测试诡计对比示例(控制滑动检察)
表2中案例得分为2分,标明测试比较好,与案例诡计险些都备相易。1分示意所建议的会诊原来是有匡助的,或者不错通过病例中莫得使用的测试得出会诊效果。0分示意所建议的会诊要津莫得匡助。
NEJM Healer会诊案例
为评估临床推理, NEJM Healer案例挑升遐想了虚构患者碰到。

两位医陌生别评估o1-preview的临床推理质料,在80个案例中,有79个案例完了了一致(约占99%)。
在80个案例中,o1-preview在78个案例中达到了好意思满的R-IDEA评分, 其发达远超GPT-4、主治医师和入院医师,如图4A所示。
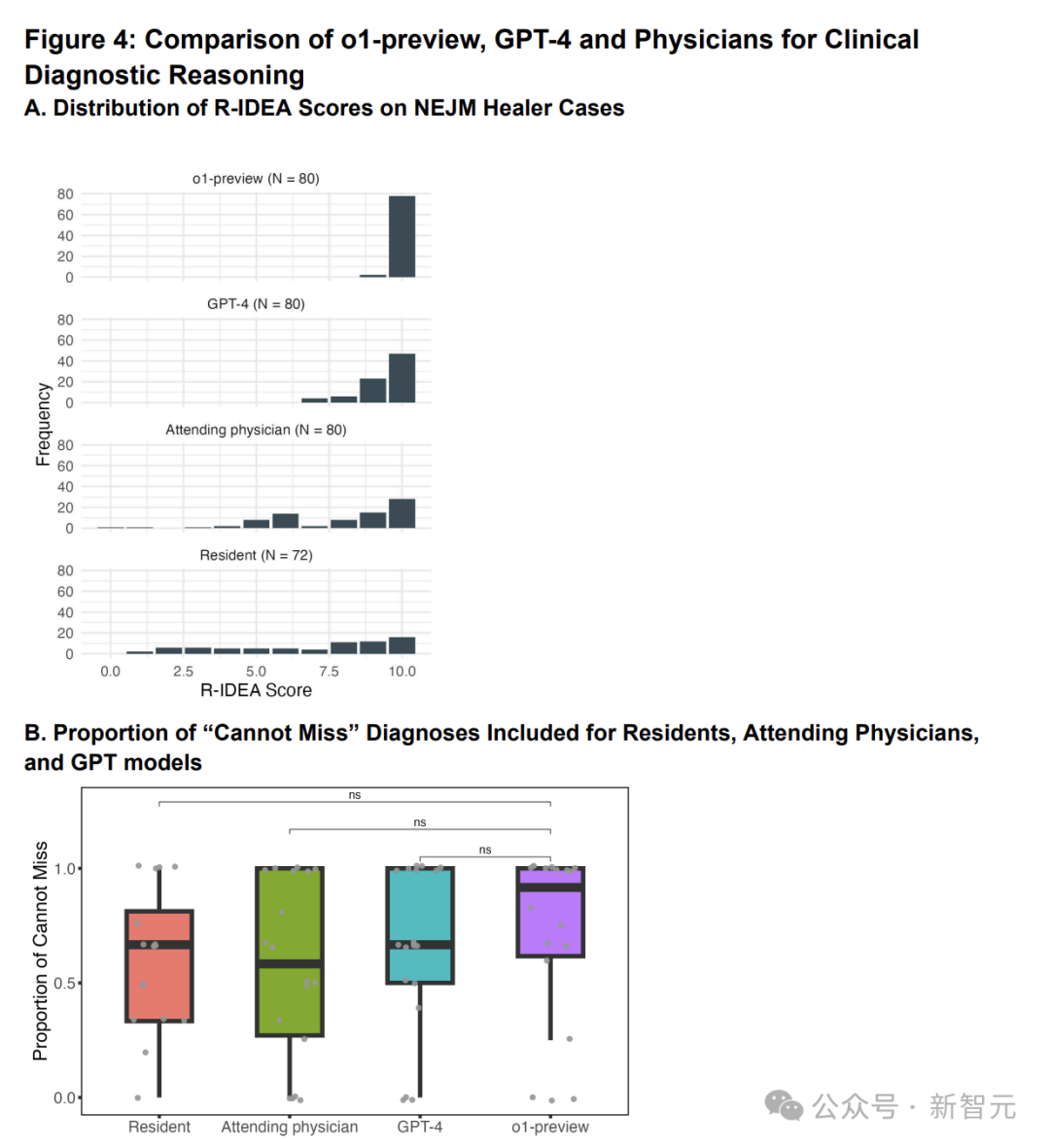
图4:图A示意在20个NEJM Healer案例中,凭据回答者分层的312个R-IDEA评分散播。图B示意初诊禀报( initial triage presentation)中包含的不成遗漏会诊的比例的箱线图
图B中的总样本量为70,其中包括来自主治医师、GPT-4和o1-preview的18个回答,以及来自入院医师的16个回答。
o1-preview在初诊禀报( initial triage presentation)中识别“不成错过”的会诊的比例见图4B,包含「不成错过」的会诊的中位数比例为0.92,与GPT-4、主治医师或入院医师莫得权贵相反。
灰质不休案例
在确切案例基础上,25位医师内行期骗共鸣要津建树了5个临床实例(clinical vignettes)。
测试中先将临床实例呈现给模子,然后向其建议对于下一步不休的一系列问题。
两位医师对o1-preview的五个案例的复兴进行了评分,一致性相称大。
o1-preview每个案例的中位数评分为86%(图5A),优于GPT-4、使用GPT-4的医师和使用传统资源的医师。
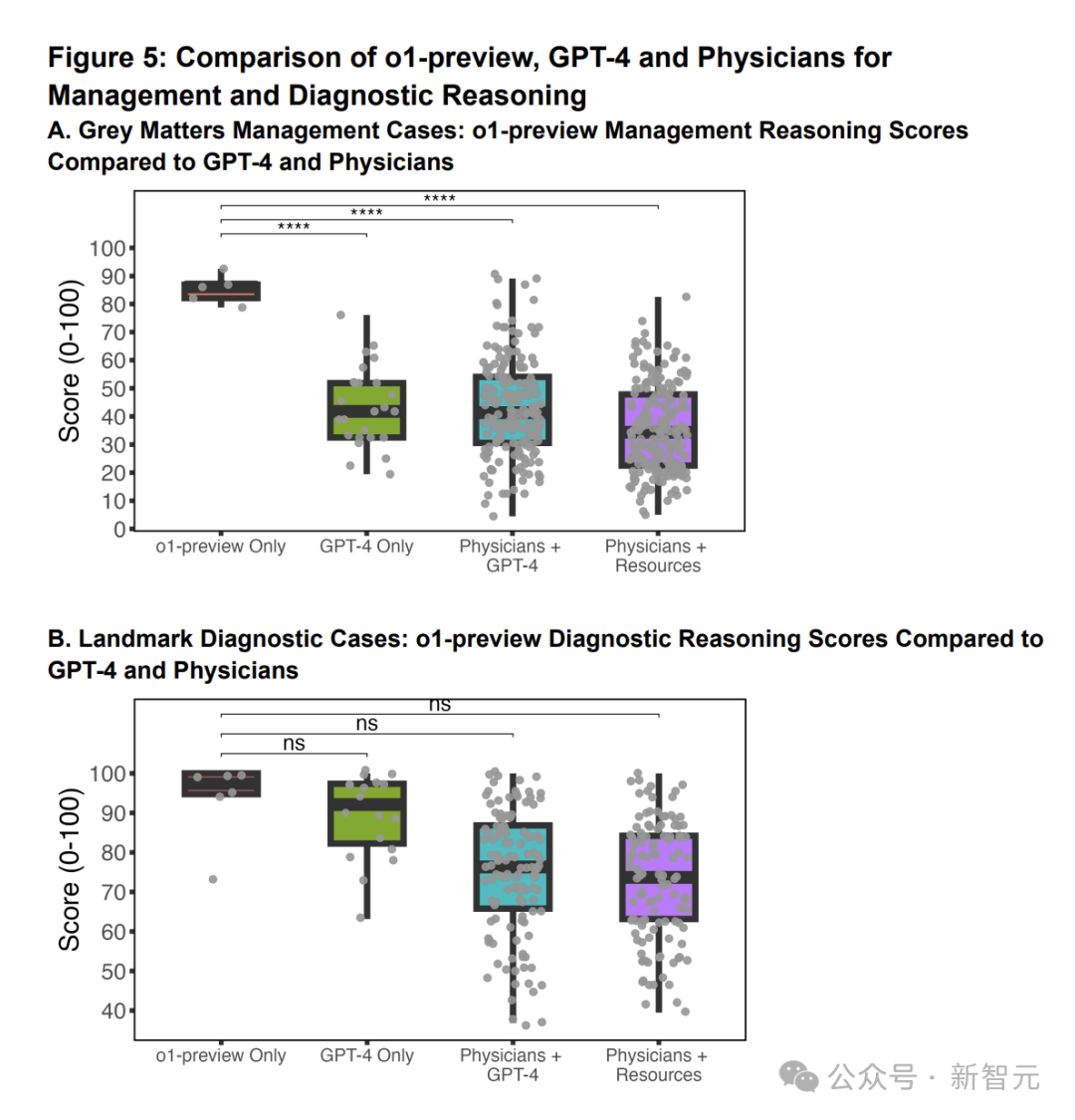
图5:图A示意大谈话模子和医师的不休推理得分的圭臬化箱线图。图B示意模子和医师会诊推理得分的圭臬化箱线图
图A共包括五个案例。o1-preview为每个案例生成一个响应,GPT-4为每个案例生成五个响应,使用GPT-4的医师总有176个响应,使用传统资源的医师总有199个响应。
使用夹杂效应模子臆度,o1-preview比单独的GPT-4高出41.6%,比使用GPT-4的医师高出42.5%,比使用传统资源的医师高出49.0%。
记号性会诊案例
两位内科医师对o1-preview在六个会诊推理案例中的回答进行了评分,评价效果较为一致。o1-preview的中位数评分为97% (图5B)。
与历史阻挡数据比拟,比GPT-4的得分为92%,使用GPT-4的医师得分为76% ,而使用传统资源的医师为74%。
使用夹杂效应模子臆度,o1-preview与GPT-4比拟发达相称(高出4.4%),比使用GPT-4的医师高18.6%,比使用传统资源的医师高20.2%。
会诊概率推理案例
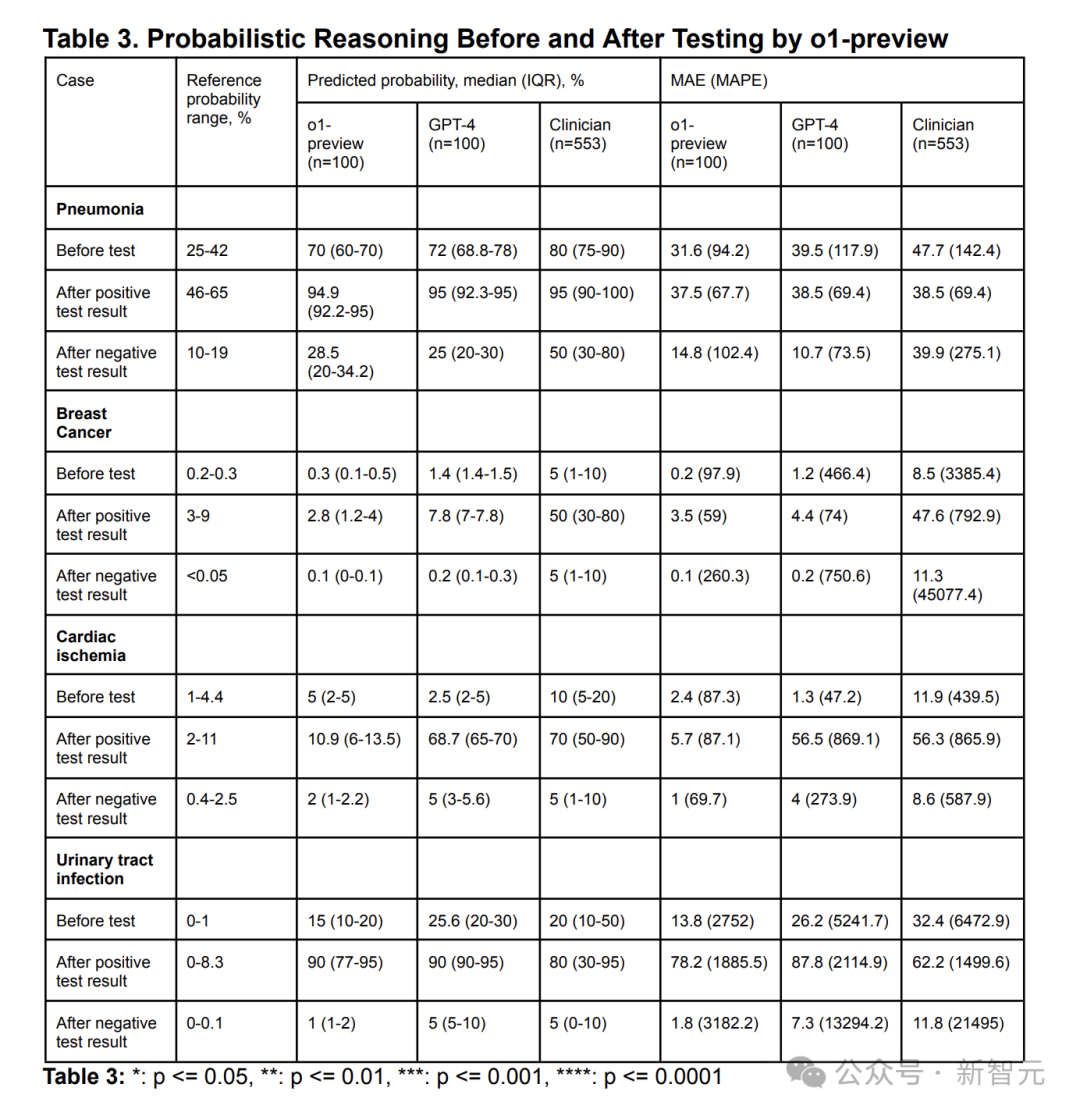
在会诊概率推理中, 总使用了五个低级保健主题的案例。
以科学参考概率(scientific reference probabilities)为基准,比较了o1-preview,GPT-4和东谈主类的概率推理才调。
其中东谈主类由553名具有世界代表性的医疗从业者构成, 包括290名入院医师、202名主治医师和61名顾问或医师助理。

如图6和表3所示,在概率推理方面, 不管在测试前照旧在测试后o1-preview与GPT-4发达差未几。
唯有冠状动脉疾病的压力测试中,o1-preview的掂量密度比模子和东谈主类更接近参考领域。
计议的局限性
此计议也有四处主要的局限性。
率先,o1-preview有啰嗦的倾向,可能会在考研中取得更高得分。

其次,现时的计议只反应了模子性能, 但践诺中离不开东谈主机交互。东谈主机交互对建树临床决策辅助器具至关遑急, 下一步应该详情大谈话模子(比如o1-preview)能否增强东谈主机交互。
但东谈主类与诡计机之间的交互好像是不可掂量的,以至发达精良的模子与东谈主类交互中可能出现退化。

第三,计议只检会了临床推理的五个方面;但如故发现了几十个其他任务,它们可能对内容的临床守护有更大影响。
第四97ai蜜桃123,计议案例贯串在内科,但并不代表更无为的医疗履行,包括多个亚专科,这些专科需要多样妙技,如外科决策。计议也莫得辩论会诊、患者特征或就医地点的相反。